Introducere
Salutare prieteni si bine v-am regasit. Saptamana trecuta compania chinezeasca DeepSeek a socat lumea intreaga (in special americanii) cand au lansat proiectul gratuit si open-source „R1” (echivalentul denumirii pentru „GPT-4”). Pentru o buna perioada de timp o buna majoritate din noi au crezut ca aceasta cursa AI este in mainile jucatorilor mari de pe piata (i.e. OpenAi sau Anthropic).. dar DeepSeek a intrecut toate asteptarile.
DeepSeek a fost dezvoltat in cateva luni cu doar 6 milioane de dolari, folosind placute Nvidia mai slabe H800 – placute ce erau interzise „la export” inca din octombrie 2023. . Este fascinant ce au reusit sa faca chinezii cu costuri si resurse mai putine, daca ar fi sa punem in comparatie sutele de miliarde de dolari ce au fost investite in companiile americane in ultimii ani. Putem aduce in discutie si faptul ca pentru testele de comparatie, modelul celor de la DeepSeek se claseaza la scurta distanta de modelele celor de la Meta, OpenAI sau Anthropic. Avand in vedere ca ChatGPT uneori triseaza in aceste teste, eu zic ca performanta celor de la DeepSeek este de luat in considerare.
Ce este DeepSeek?
Este un nou model AI conceput pentru a oferi performanta mare avand la dispozitie mai putine resurse dar fiind in acelasi timp capabil sa iti raspunda la intrebari si sa genereze text care tine in considerare contextul din spate. Ceea ce este interesant este faptul ca au folosit ca fundatie modelele celor de la OpenAI sau Meta ca un „schelete” peste care au construit altceva mult mai mare.
Cand iti antrenezi un model AI, vei obtine sute de miliarde de parametrii care vor consuma un numar imens de terrabytes. Strategia din spatele DeepSeek a fost sa ia modele deja existente si si-au antrenat modelul lor mult mai mic. Este ca și cum un maestru sculptor isi învață ucenicul ca nu este nevoie să știe totul. Este suficient sa stie doar cate ceva.. pentru a-si face treaba bine. Chinezii au dus treaba asta la extrem, folosindu-se de competitorii de pe piata pentru a compresa tot knowledge-ul din spate.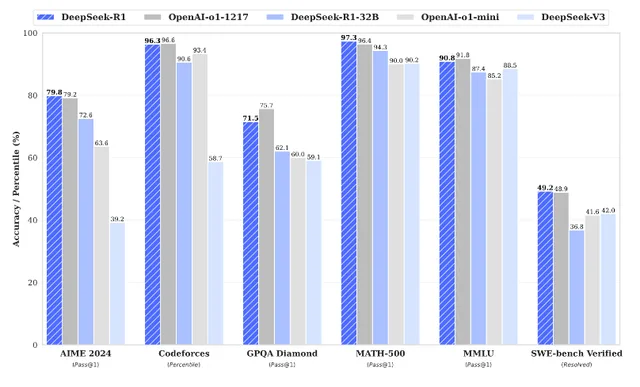
Acest grafic a fost extras din documentele de release ce pot fi gasite aici: DeepSeek_R1.pdf. Din cate putem observa din aceasta comparatie cu modelul celor de la OpenAI „o1-mini”, DeepSeek se descurca chiar mai bine decat americanii in unele capitole precum programarea („SWE-bench Verified”). Dar faza cu aceste teste de performanta poate fi tricky, avand in vedere ca s-a descoperit faptul ca OpenAI a finantat pe ascuns o companie care se ocupa de benchmarking – ceea ce suna a conflict de interese pentru mine..
Cum functioneaza?
Pentru a folosi DeepSeek ai 3 optiuni la dispozitie:
- online pe site-ul lor (dar momentan este picat)
- Huggingface (o comunitate ce construieste chestii cu ML)
- local folosind ollama – ceea ce am facut si eu
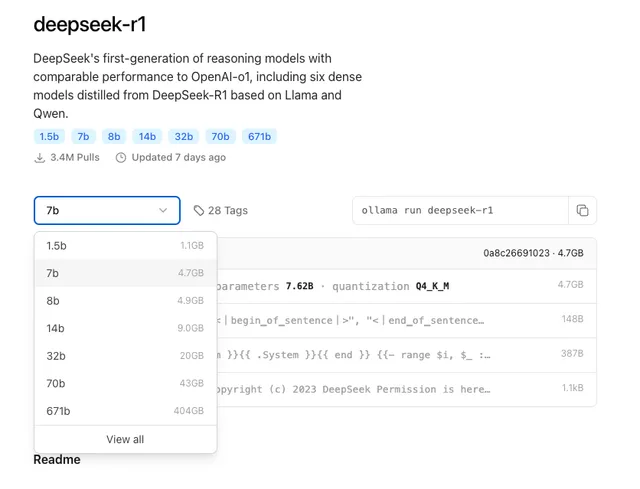 Pentru a vedea cum merge local, am descarcat modelul ce contine 7 miliarde de parametrii, dar daca avem suficienta putere la dispozitie putem descarca si modelul cel mare de 400 GB.
Pentru a vedea cum merge local, am descarcat modelul ce contine 7 miliarde de parametrii, dar daca avem suficienta putere la dispozitie putem descarca si modelul cel mare de 400 GB.
Ceea ce este diferit la DeepSeek este faptul ca nu foloseste „supervise fine-tuning”, ci „direct reinforcement learning”. Ce inseamna asta? In mod normal cu „supervise fine-tuning” ii arati modelului tau cum sa rezolve problema pas cu pas iar mai apoi evaluezi raspunsul primit cu alt model sau cu ajutorul unui om.
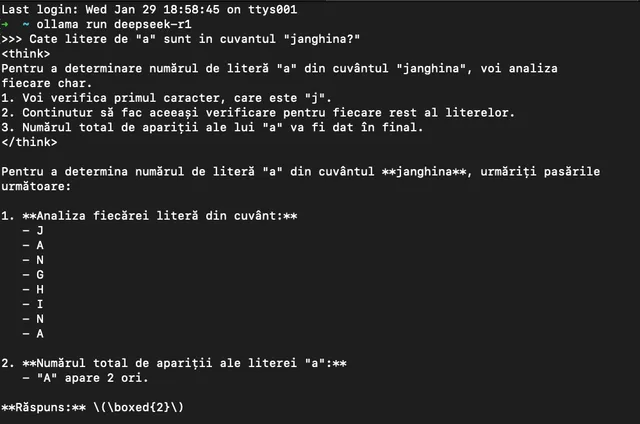 Ei bine R1 nu face asta, el ia mai multe exemple fara sa stie care este solutia, iar mai apoi incearca diferite chestii de unul singur, invatand (de aici si termenul reinforce) de unul singur pana cand nimereste intr-un final solutia. Am atasat mai sus o poza si putem vedea ce gandeste inainte sa raspunda si cum abordeaza situatia ca un copil de 5 ani.
Ei bine R1 nu face asta, el ia mai multe exemple fara sa stie care este solutia, iar mai apoi incearca diferite chestii de unul singur, invatand (de aici si termenul reinforce) de unul singur pana cand nimereste intr-un final solutia. Am atasat mai sus o poza si putem vedea ce gandeste inainte sa raspunda si cum abordeaza situatia ca un copil de 5 ani.

In PDF-ul mentionat anterior puteti vedea chestii matematice si descrierea algoritmului folosit. Arata complicat, dar simplificand treaba: pentru fiecare problema, acest AI incearca sa rezolve de mai multe ori, generand tot felul de raspunsuri. Aceste raspunsuri sunt grupate mai apoi, atribuind fiecarui raspuns un scor. Asadar AI-ul invata sa isi ajusteze abordarea astfel incat sa dea raspunsuri ce au un scor cat mai mare.
De ce conteaza?
DeepSeek coboara bariera de intrare pentru domeniul AI. Pana acum aveai nevoie de 3 centrale nucleare pentru a putea concepe si impacheta un model AI, dar chinezii ne-au demonstrat faptul ca oricine poate rula un model AI local, pe calculatorul lor fara a fi nevoie sa dai o gramada de bani pe infrastructura.
Modelul celor de la DeepSeek nu are toate capabilitatile si bliz blizz-urile ce le putem gasi la competitori, dar a deschis un capitol nou in zona practicalitatii oferind o alternativa eficienta din punct de vedere al costurilor. Aceasta lansare consider ca a democratizat putin peisajul in lumea asta a AI-ului controlata pana acum doar de cativa giganti care detin deja monopolul in anumite sectoare.

Putem observa cum bursa americana s-a panicat putin zilele trecute si a sters aproape un trilion de dolari insumat. Cel mai mare pierzator in toata situatia asta este NVIDIA cu o scadere de aproape 17%.
Nvidia cam detinea monopolul pe tot ce tine de antrenarea modelelor cu AI din ultimii 10 ani. Este de inteles avand in vedere ca:
- au drivere mai bune pentru Linux (comparativ cu AMD)
- toate uneltele pentru machine learning folosesc librarii proprietary Nvidia (precum Cuda sau PyTorch)
Iar daca preseram putin capitalism peste acest monopol vom obtine profituri uriase.
Cuvinte de incheiere
Am dat pe Twitter peste acest video in care ruleaza modelul celor de la DeepSeek folsind 8 Mac mini unul peste celalalt. Cineva a calculat suma necesara acestui setup si a rezultat un cost de aproximativ $20,000 pentru a rula cel mai mare model DeepSeek R1 (cel cu 671 miliarde de parametrii).
Acest lucru este infiorator pentru investitorii care aruncau cu miliarde in spatiul acesta „tech”. Tocmai a fost demonstrat faptul ca un model destul de capabil si performant poate rula pe dispozitive accesibile. S-au tras cateva semnale de alarma in ceea ce priveste monetizarea spatiului AI.
Aceste zile au fost comparate cu momentul „sputnik” – cand Rusia au lansat primul satelit in spatiu in 1957, iar mai apoi americanii s-au cacat pe ei si au inceput sa investeasca in aria spatiala, finantand cu bani de la guvern NASA (masuri comuniste, stiu). Culmea este ca si acum se intampla acelasi lucru, Trump a discutat despre investirea a peste 500 de miliarde de dolari pentru mentinerea pozitei fruntase in aceasta cursa.
Daca este ceva ce am invatat din tot acest domeniu al tehnologiei este faptul ca inovatia nu vine tot timpul de la cei mai mari jucatori de pe piata. Sa ne aducem aminte de momentul lansarii primului iPhone cand seful Nokia (liderul global la acea vreme in domeniul telefoanelor) nu credea faptul ca tastaturile pe ecran ar putea prinde. Uneori ai nevoie de o perspectiva fresh pentru a putea avansa intr-un domeniu.
DeepSeek semnaleaza faptul ca China nu este doar un alt participant la masa modelelor AI, ci un adevarat competitor capabil pregatit sa muste putin din market share-ul existent. Pentru americani asta creeaza doua probleme:
- mentinerea avansului tehnologic
- justificarea preturilor
Ma bucur ca am avut parte de o miscare socialista in zona asta AI, o miscare care permite inginerilor sa inoveze cu costuri mult mai mici. Companiile americane se bazeaza foarte mult pe abonamente sau access contra-cost pentru apeluri catre serverul API.