Algoritmul lui Kruskal are același rol ca și algoritmul lui Prim, și anume cel de a găsi arborele parțial de cost minim. Acest algoritm a fost descoperit în anul 1956, la 26 de ani după algoritmul lui Prim. Deși ambii algoritmi au același scop, algoritmul lui Kruskal este greedy deoarece la început toate muchiile din graf trebuie sortate crescător.
Cum funcționează acest algoritm?
Pentru a intelege mai bine cum functioneaza acest algoritm, vom rezolva impreuna problema Arbore partial de cost minim – de pe infoarena. Vom desena mai jos exemplul din fisierul de intrare:

Iar la final graful nostru va arata asa:
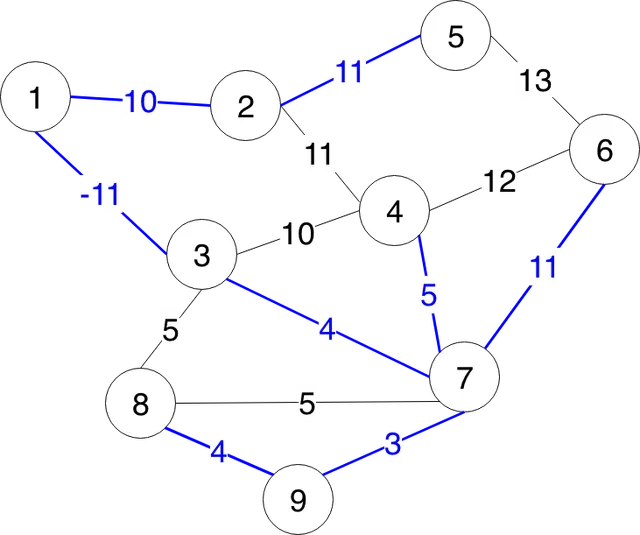
Primul pas din algoritmul lui Kruskal este sa sortam nodurile in ordine crescatoare. Dupa ce am sortat nodurile in ordine crescatoare, incepem cu cea mai mica pereche si creeam primul nostru arbore.
Pe masura ce algoritmul avanseaza de fiecare data trebuie sa unim doi arbori mai mici. Trebuie sa avem mare grija ca cei doi arbori sa nu fie deja conectati (pentru a respecta proprietatea de arbore). Ca sa ne apropriem de raspunsul final, trebuie sa unim arborele mai mic, cu arborele mai mare.
Complexitatea algoritmului lui Kruskal
Pentru a analiza complexitatea, trebuie sa ne uitam la functia „Solve”. Aceasta parcurge toate muchiile (deci avem din start un M). Dupa care functia repetitiva mai deschide o functie recursiva (in functia Solve – apelam functia Find).
Deoarece functia Find are complexitatea log2N unde N este numarul total de noduri – ajungem la complexitatea finala a algoritmului O(M * log2N) – unde M este numarul total de muchii.
Implementarea in C++
#include <fstream>
#include <iostream>
#include <algorithm>
using namespace std;
ifstream fin("apm.in");
ofstream fout("apm.out");
const int NMax = 400005;
pair <int,int> P[NMax];
int N, M, Total, TT[NMax], k, RG[NMax];
struct Edge
{
int x,y,c;
}V[NMax];
bool Compare(Edge a, Edge b)
{
return a.c < b.c;
}
void Read()
{
fin >> N >> M;
for(int i = 1; i <= M; i++)
fin >> V[i].x >> V[i].y >> V[i].c;
sort(V+1, V+M+1, Compare);
for(int i = 1; i <= M; i++)
cout << V[i].x << " " << V[i].y << " " << V[i].c << "\n";
}
int Find(int nod)
{
while(TT[nod] != nod)
nod = TT[nod];
return nod;
}
void Unite(int x, int y)
{
if(RG[x] < RG[y])
TT[x] = y;
if(RG[y] < RG[x])
TT[y] = x;
if(RG[x] == RG[y])
{
TT[x]=y;
RG[y]++;
}
}
void Solve()
{
for(int i=1;i<=M;i++)
{
//cout << "Incerc " << V[i].x << " cu " << V[i].y << "\n";
if(Find(V[i].x) != Find(V[i].y))
{
//cout << "Unesc " << V[i].x << " cu " << V[i].y << "\n\n";
Unite(Find(V[i].x), Find(V[i].y));
P[++k].first = V[i].x;
P[k].second = V[i].y;
Total += V[i].c;
}
}
}
int main()
{
Read();
for(int i = 1; i <= M; i++)
{
TT[i]=i;
RG[i]=1;
}
Solve();
fout << Total << "\n";
fout << N-1 <<"\n";
for(int i = 1; i <= k; i++)
fout << P[i].first << " " << P[i].second << "\n";
return 0;
}Spre deosebire de algoritmul lui Prim, cel al lui Kruskal se folosește mai mult de muchii decat de noduri (pentru că la început le sortează).